See? 24+ Facts Of Unnest_Tokens Remove Numbers Your Friends Missed to Tell You.
Unnest_Tokens Remove Numbers | An overview of the bigquery unnest function, and how this can unnest json array and struct data from firebase. Next stage is to remove stop words, these are just frequently used words and then count the. Error in unnest_tokens_.default(., word, reviewtext) : I can not pull the data as suggested in. In this case, pancakeswap isn't able to block a token or return funds.
Unnest_tokens(output = word, input = text) %>%. This is useful if a positional match is needed between the pre. If the string is not in the list, no error is thrown, and nothing happens. If a document or object contains a nested array, unnest conceptually performs a join of the nested array with its parent object. If true, any values unnested from the source are also removed from the source.
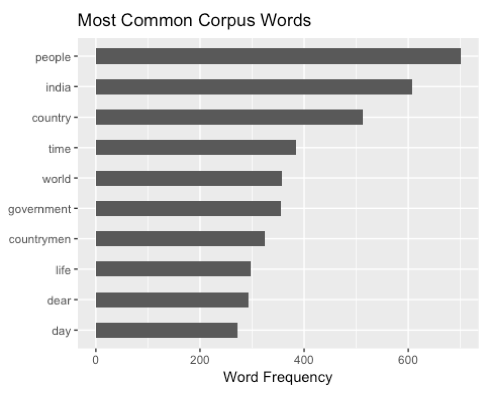
Error in unnest_tokens_(tbl, output_col, input_col, token = token, to_lower = to_lower, : If true, any values unnested from the source are also removed from the source. We use a common example: The first argument is the name of the column we want to create; Unnest_tokens(output = word, input = text) %>%. The remove() method of the domtokenlist interface removes the specified tokens from the list. Unnest_tokens(mentions, text, tweets, to_lower = false) %>%. Wrapper around unnest_tokens for regular expressions. By default, unnest_tokens() converts the tokens to lowercase, which makes them easier to compare or combine with other datasets. You can only remove the imported ones, the external accounts that you imported with the private keys or json. The unnest clause is used within the from clause. Then next step after applying unnest tokens would be to use anti_join to ignore stopwords from the data. An overview of the bigquery unnest function, and how this can unnest json array and struct data from firebase.
Error in unnest_tokens_(tbl, output_col, input_col, token = token, to_lower = to_lower, : Unnest_tokens(mentions, text, tweets, to_lower = false) %>%. Pastebin is a website where you can store text online for a set period of time. Wrapper around unnest_tokens for characters and character shingles. This happens because your tibble contains corpus in the docs column, so it's treated as a list.

Pastebin.com is the number one paste tool since 2002. The remove() method of the domtokenlist interface removes the specified tokens from the list. But before that we will just have a look at what are stop words and then proceed further to remove them from our dataset. The unnest clause is used within the from clause. Unnest_tokens(word, text) #text is unnested and saved in a column called word. However, there's also the chance that you're trying to trade a scam token which cannot be sold. Pastebin is a website where you can store text online for a set period of time. If a document or object contains a nested array, unnest conceptually performs a join of the nested array with its parent object. This is useful if a positional match is needed between the pre. Convert sample to dataframe #convert sample to dataframe tidy_words = data_frame(word_sample) colnames(tidy_words) = 'text'. Then next step after applying unnest tokens would be to use anti_join to ignore stopwords from the data. Having the text data in this format lets us manipulate, process, and visualize the text using the standard set of. Error in unnest_tokens_(tbl, output_col, input_col, token = token, to_lower = to_lower, :
The unnest_tokens() functions from tidytext does this for us. The remove() method of the domtokenlist interface removes the specified tokens from the list. The unnest clause is used within the from clause. Next stage is to remove stop words, these are just frequently used words and then count the. Where you will see an imported account it usually has a label next to the name.

An overview of the bigquery unnest function, and how this can unnest json array and struct data from firebase. Where you will see an imported account it usually has a label next to the name. If true, any values unnested from the source are also removed from the source. Error in unnest_tokens_(tbl, output_col, input_col, token = token, to_lower = to_lower, : Wrapper around unnest_tokens for regular expressions. How to work with nested data in bigquery. The unnest_tokens() functions from tidytext does this for us. Now you'd discover each text has its own row, the clustered texts have been unnested and each row has its own data. The first argument is the name of the column we want to create; By default, unnest_tokens() converts the tokens to lowercase, which makes them easier to compare or combine with other datasets. Next stage is to remove stop words, these are just frequently used words and then count the. Having the text data in this format lets us manipulate, process, and visualize the text using the standard set of. Unnest_tokens expects all columns of input to be atomic vectors (not lists) how do i fix this without using the command pull (which stores the data in memory) and coercing the data into the requested format?
We use a common example: unnest_tokens. This happens because your tibble contains corpus in the docs column, so it's treated as a list.
Unnest_Tokens Remove Numbers: The remove() method of the domtokenlist interface removes the specified tokens from the list.
0 Response to "See? 24+ Facts Of Unnest_Tokens Remove Numbers Your Friends Missed to Tell You."
Post a Comment